А был ли меморандум?
Опубликовано 18 декабря 2013
По наводке нашёл информацию о том, что (якобы) существует некий меморандум Роскомнадзора «О сотрудничестве в сфере обеспечения исключительных прав при использовании фильмов» и о том, что правообладатели и “мелочёвка” его подписала, а “крупняк” воздержался. Информация ссылается на Interfax но на сайте я про меморандум найти ничего не сумел…
_________________
Тем не менее, такие источники как (Итрар-тасс), (Тасс-телеком), (ComNews), (JCNews) подтверждают наличие такого меморандума, который от имени зарубежных правообладателей (именно их интересы меморандум защищает) подписала компрадорская РАПО (Российская АннтиПиратская Организация), российские телеканалы (которые никогда ничьи права на видеоконтент отродясь не нарушали) и кое-какая мелочёвка.
Что до “крупняка”, то он на своей шее “петлю” затягивать не рвётся. Google говорит, что руководствуется DMCA, а Яндекс высказывает претензии к документу:
В Yandex считают, что при подготовке меморандума не были учтены важные моменты: недопустимость премодерации, жесткие сроки на внедрение систем идентификации пиратского контента и обязательное наличие URL-адреса в жалобе правообладателя контента. Компания также давно работает с правообладателями по удалению неправомерно размещенного контента. Чтобы заявить о своих правах, необходимо прислать в «Яндекс» жалобу.
Понятно, что компрадорская РАПО готова подписать любой документ, который покажет доверителям как активно она борется за их интересы. На Российские технологические фирмы РАПО глубоко плевать. Непонятно только почему Роскомнадзору (который, в теории, служит России) также плевать на интересы Российских фирм и почему ему приписывают авторство подобного меморандума…
Комментарии к записи А был ли меморандум? отключены
Стакан наполовину…
Опубликовано 14 сентября 2013
В старом анекдоте разница между оптимистом и пессимистом основывалась на выборе между мыслями “стакан наполовину ПУСТ” или “стакан наполовину ПОЛОН”. Вот и опубликованные результаты исследования ВЦИОМ можно рассматривать с двух точек зрения.
Точка зрения пессимиста изложена в публикации (цитирую целиком):
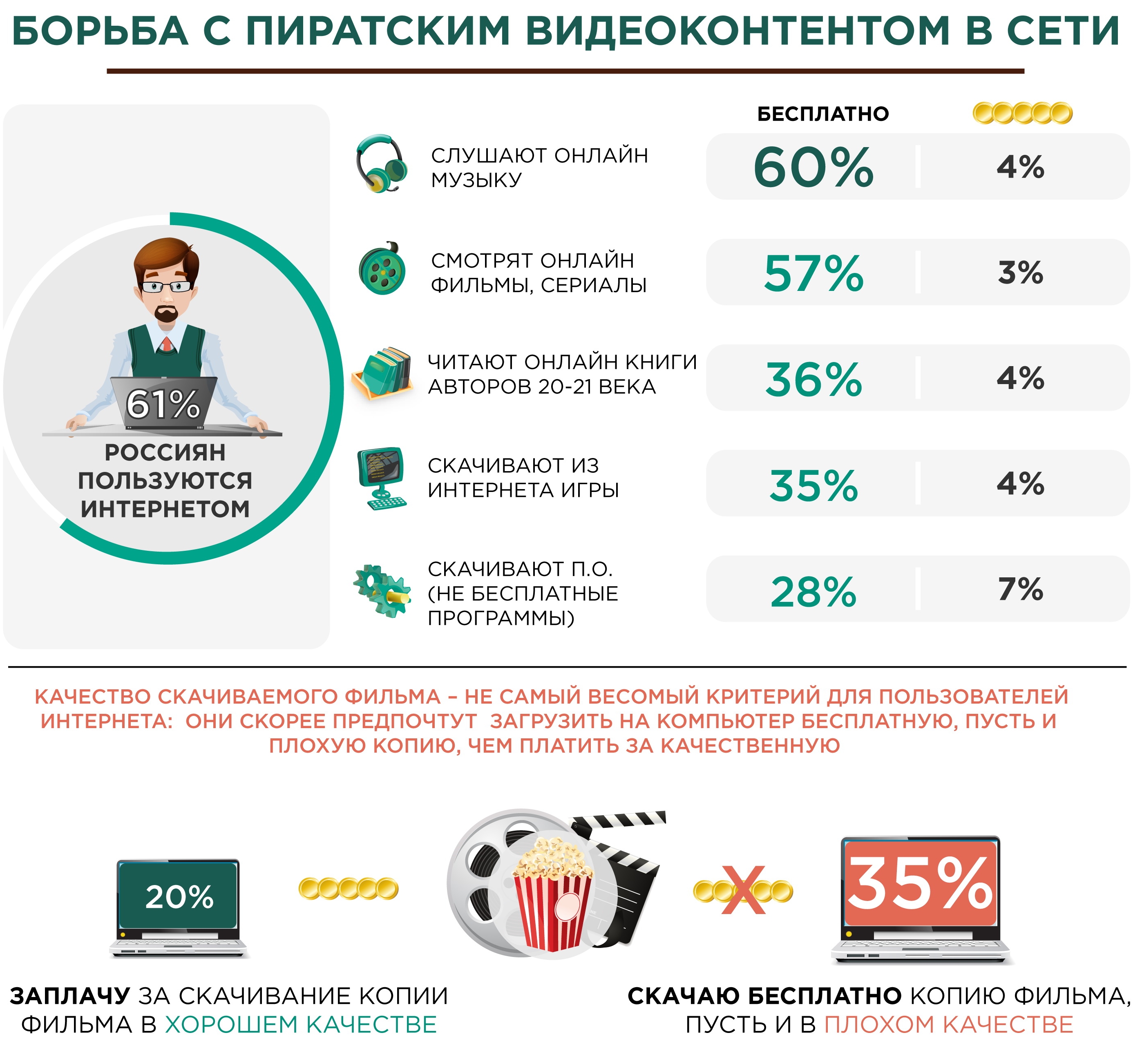
МОСКВА, 12 сентября /Корр. ИТАР-ТАСС Дмитрий Волин/. Российские пользователи интернета предпочитают скачивать музыку и фильмы в сети бесплатно, при этом лишь 11% из этих граждан готовы будут платить за интернет-контент, если он весь станет платным. Об этом свидетельствуют опубликованные сегодня результаты опроса Всероссийского центра изучения общественного мнения /ВЦИОМ/.
“Наиболее потребляемый российскими пользователями контент в сети – музыка, ее скачивают почти две трети опрошенных /63%/ и фильмы /60%/”, – отмечают социологи. Менее востребованными оказались книги современных авторов /их скачивают 40% респондентов/, игры /39%/ и программное обеспечение /39%/.
“В целом российские интернетчики обычно стараются скачивать контент в сети бесплатно. В особенности это касается скачивания музыки /60% признались, что, как правило, не платят за это/ и фильмов /их скачивают 57% опрошенных/”, – сообщается в материалах опроса.
По данным ВЦИОМ, качество скачиваемого фильма – не самый весомый критерий для пользователей интернета: они скорее предпочтут загрузить на компьютер бесплатную, пусть и плохую копию /так ответили 35% граждан/, чем платить за качественную /20%/. Такая стратегия наиболее характерна для молодых, активных интернетчиков.
“Если все фильмы и сериалы в интернете станут платными, приобретать их копии за деньги готова относительно небольшая часть пользователей, обычно скачивающих их безвозмездно /11%/, – отмечают социологи. – Более актуальные стратегии – поиск способов обойти запрет /36%/ и обмен с друзьями и знакомыми дисками с фильмами /32%/”. Еще 16% респондентов признались, что начнут чаще посещать кинотеатры, а 14% просто перестанут скачивать фильмы из сети.
Всероссийский опрос ВЦИОМ проводился в августе 2013 года. Было опрошено 1600 человек в 130 населенных пунктах в 42 областях, краях и республиках России. Статистическая погрешность не превышает 3,4%.
А теперь попробуем посмотреть на те же цифры глазами оптимиста. И за основу возьмём публикацию ВЦИОМ. Поскольку 187-ФЗ делает вид, что пытается защищать видеоконтент:
Понятно, что тут есть два момента:
- Пользуются бесплатным контентом потому, что есть возможность
- Пользуются нелегальным контентом потому, что легальный недоступен
Вот уточняющая таблица:
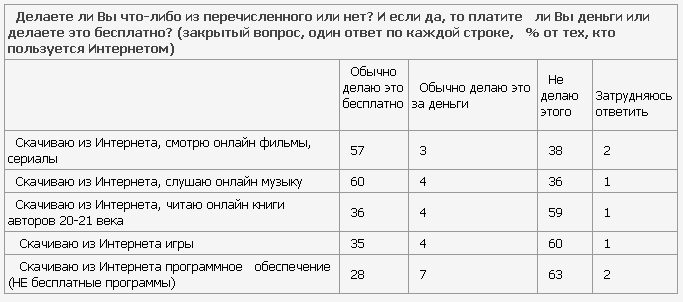
Два столбца справа – это как раз те, кто (с точки зрения оптимиста) готов при определённых условиях перейти на легальные рельсы
Итак, если легальный контент будет хорошего качества, то 20% готовы за него заплатить. Неплохой потенциал для легальных продаж. 35% готовы пожертвовать качеством и, возможно, негативными последствиями попытки качать с неведомого сайта только ради того, чтобы получить бесплатно. И самая большая доля (45%) – это колеблющие, т.е. (по сути) те, кто при хорошем юзабилити, удобных условиях доступа к контенту и вменяемой ценовой политике БУДУТ готовы платить за контент высокого качества. Т.е. у нас две трети (65%) пользователей – это те, с кем бороться не надо. Им надо обеспечить легальный контент и юзабилити. Понятно, что любые репрессии вместо предоставления легальной альтернативы моментально приведут эти неустойчивые 45% в ряды принципиальных потребителей только и исключительно халявы. Понятно, что прежде чем “подгребать” твердолобых правообладателям следует научиться продавать легальный контент тем, кто его готов покупать (65%). И только наладив взаимодействие с теми, кто готов удовольствоваться легальной альтернативой можно (не создавая неудобств лояльным пользователям легального контента) начинать “поджимать” то самое, как выяснилось, МЕНЬШИНСТВО, которое заявляет, что пойдёт до конца…
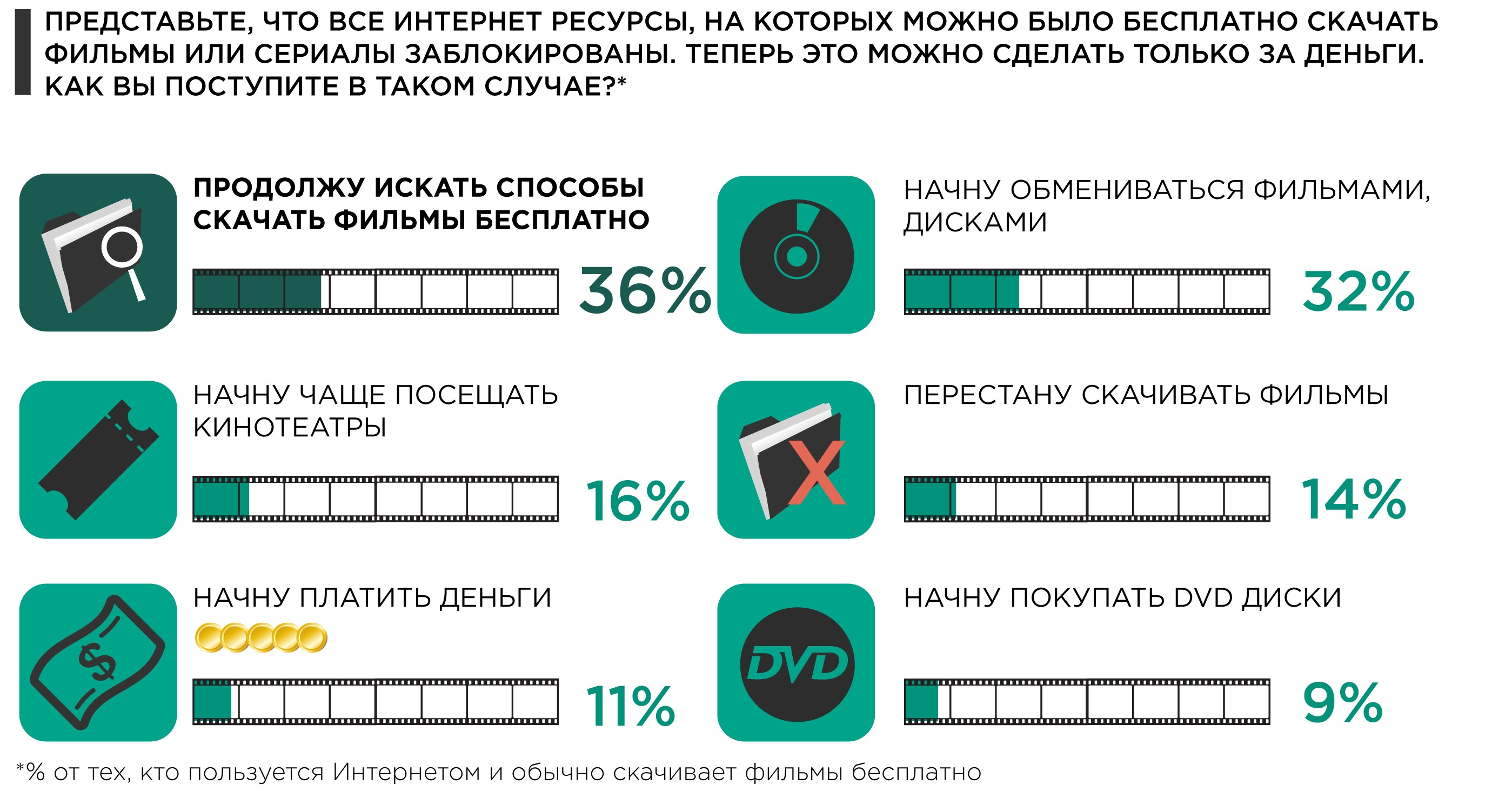
Здесь отражены результаты репрессий:
Готовы были платить при наличии легального и качественного контента 20%. а при репрессиях готовы платить только 11% (неизвестно за что, но, видимо, они надеются. что появится легальная альтернатива) и 9% за альтернативу в виде DVD (кто сказал, что они будут легальными и от их продажи что-то выиграют правообладатели?). Непримиримых осталось 36% (это в пределах статистической погрешности те же 35% в ответе на предыдущий опрос). А оставшиеся будут искать иные альтернативы и, уж конечно, платить за отсутствующий (недоступный легально) контент не станут
А если посмотреть глазами оптимиста на ситуацию с е-книгами, то получается, что потенциал тех, кто может (при наличии легальной альтернативы, юзабилити и вменяемой цене) стать лояльным потребителем легального контента заметно выше половины – целых 60%
Одна “деталь”… Лояльными они станут при получении легальной альтернативы, а при бездумных репрессиях (пусть даже не против потребителей, а только против поставщиков) они тоже перейдут в категорию “стойких приверженцев халявы”…
Когда-то бездумные репрессии (они назывались “Сухой закон”, который был принят “из лучших побуждений”) стали экономической базой для создания организованной преступности в США, которая создала себе первичный капитал на нелегальном удовлетворении тех потребностей, которые легально не удовлетворялись.
За законодательными репрессиями против “пиратов” никакой легальной альтернативы не просматривается. А, ведь, казалось бы, как просто: объявляем, что защита копирайта осуществляется только для тех правообладателей, которые обеспечили легальную альтернативу… Ан нет… Намеренно создаётся ситуация “Сухого закона” (легального удовлетворения потребностей нет, а нелегальное формально запрещено)…
Базой для создания в России ЧЕГО (и в чьих интересах) являются копирайтные законодательные репрессии? Очень похоже на то, что лоббируется эта “мерзопакость” той самой организованной преступностью, кормушкой для которой станет репрессивное законодательство…
Комментарии к записи Стакан наполовину… отключены
Проект изменения копирайтного законодательства
Опубликовано 5 августа 2013

На (Законопроект № 47538-6/7 (изменения в ГКIV)) есть ссылка из поста (Кодекс против интернета). Цитирую почти целиком:
Дума наша готовит глобальный законопроект, посвященный реформе всего-всего Гражданского кодекса, всех его четырех частей.
Изначально эти изменения были внесены в Думу одним большим куском и рассмотрены так в первом чтении. Но потом думцы решили, что не справятся с таким закономонстром (я их понимаю), и разбили его на кучу маленьких закономонстриков.
Беда в том, что при этом образовавшиеся законопроекты не были нигде опубликованы. Выкладывать их должны на думском законотворческом сайте, но сделано этого не было. Вдобавок, похоже, исходный проект с этого сайта был вообще удален, или заменен одним из своих отпочкований.
То есть, сейчас те изменения, которые вносятся в тексты между первым и вторым чтениями, недоступны никому, увы. А они вносятся, причем многие имеют принципиальный характер. Вероятно, законотворцы хотят публиковать их перед вторым чтением, а затем — быстренько принимать, после чего вносить какие-то поправки будет поздно. В результате об актуальной версии проекта реформы четвертой части ГК имеется только одно упоминание в интернетах. Мне кажется, вот так, келейно и подковерно, изменять один из важнейших для Интернета законов — не совсем правильно…
В общем, как вы догадались, я намерен исправить эту ошибку. Собственно, вот, исправляю. По этой ссылке — текст проекта. Те изменения, которые были в него внесены после первой публикации в “Российской газете”, выделены жирным шрифтом.
А следующими семью постами пойдет краткий обзор и разбор неопубликованных поправок, с редкими вкраплениями опубликованных, из числа наиболее интересных.
UPD: те самые семь постов:
Меня заинтересовали уточнения 1, 3 и 6
___________________________
рекомендую также посты от ![]() dolboeb:
dolboeb:
- Живые записки Антона Носика – FAQ про антипиратский закон, часть I: текст закона
- Живые записки Антона Носика – FAQ про антипиратский закон, часть II: патриотизм
- Живые записки Антона Носика – FAQ про антипиратский закон, часть III: как наебали Путина
- Живые записки Антона Носика – FAQ про антипиратский закон, часть IV: Америка
Комментарии к записи Проект изменения копирайтного законодательства отключены
Хоть тут копирайта нет
Опубликовано 2 октября 2012
Libex порадовал, что в ПБ Нью-Йорка появилась оцифрованная (Коллекция ресторанных меню).
Хорошо, хоть на этот контент копирайта нет, а то для оцифровки и предоставления бесплатного доступа пришлось бы ждать 70 лет после смерти последнего из подписавших меню (в т.ч. младшего бухгалтера, рассчитавшего цену блюд…)
Дистрибуция контента в меняющемся мире
Опубликовано 21 сентября 2012
Мир УЖЕ изменился. И выхода, собственно говоря, нет. Все попытки вопить про “злобных пиратов” и требовать от первых лиц, чтобы всё было по старому заведомо обречены. Возможности вести бизнес по старым схемам уже нет. К сожалению, никто не гарантирует успешность ВСЕХ попыток вести бизнес по новому. Часть попыток удастся, а часть (и весьма значительная) провалится.
ЧасКор описал возможные принципы успешной дистрибуции цифрового контента в виде почти библейских (Десять заповедей «Новой Библии дистрибуции»). Сами заповеди я с благодарностью процитирую:
Десять заповедей «Новой Библии дистрибуции»
1. Не применять в Сети те же модели дистрибуции, что и за ее пределами.
2. Не защищать контент от распространения, а контролировать и управлять его распрост-ранением.
3. Собирать деньги не с видеобизнесменов, а с пользователей интернет-площадок видеобизнесменов.
4. Не удалять пиратский контент, а замещать его на легальный.
5. Не уходить от переговоров с пиратами, а сотрудничать с их уже налаженными сетями дистрибуции и извлекать из сотрудничества прибыль.
6. Не завышать стоимость для пользователей, а работать на объемах, так как Сеть это позволяет.
7. Не отставать технологически, а развивать собственные решения для управления и дистрибуции контента в Сети.
8. Не думать, что Сеть — это второй экран, но первый и уже завтра.
9. Не уходить от ответственности за пиратство, так как сами в нем виноваты.
10. Не думать, что может быть по-другому!
А за обсуждением проблеы – прошу (по ссылке)
Понятно, что у е-книг не всё и не совсем так, но главный принцип совпадает: те, кто не хотят меняться, вымрут все. Из тех, гто готов меняться выживут далеко не се, но выжившие “сорвут банк” и зададут новый стандарт бизнеса дистрибуции
Комментарии к записи Дистрибуция контента в меняющемся мире отключены
Снова Копирайт против ЛЕГАЛЬНОГО потребления контента
Опубликовано 10 сентября 2012
Известно, что и Apple и Google разрешают ПОКА россиянам покупать только ПО. Контент легально купить нельзя (ни музыку, ни е-книги, ни видео). Не думаю, чтобы эти фирмы брезговали российскими деньгами. Судя по всему, проблемы у них копирайтные. Вот как описывает ситуацию Ведомости (Музыкальный магазин от Apple может заработать в России к Новому году: К Новому году в России может заработать музыкальный магазин iTunes от Apple. В США один трек из iTunes стоит $0,99, России обещаны скидки: Анастасия Голицына: 10.09.2012):
Музыкальный магазин iTunes скоро откроется для российских пользователей, рассказали «Ведомостям» пять источников в компаниях, бизнес которых связан с интернетом и с покупкой прав на музыкальные произведения. По их словам, запуск запланирован на IV квартал 2012 г., но может сдвинуться и на I квартал 2013 г. — это будет зависеть от успеха переговоров с российскими звукозаписывающими компаниями и владельцами прав. Apple предпочитает выходить на новые рынки с максимально полным каталогом музыки, объясняет один из собеседников «Ведомостей». Но уже известно, что стоимость одного трека в российском iTunes будет ниже, чем в американском ($0,99), добавляет он. Это подтверждает другой источник: в русском iTunes композиция может стоить как на Muz.ru — 11-20 руб. в зависимости от исполнителя. Представитель Apple отказался от комментариев.
Apple запустила iTunes в 2003 г., сейчас магазин работает в 37 странах. С помощью iTunes можно покупать музыку, хранить ее на компьютере или в облаке (сервис iTunes Match). В России уже несколько лет работает лишь часть iTunes — магазин приложений AppStore.
О полноценном запуске iTunes в России Apple впервые задумалась в 2007 г. Остановил ее высокий уровень пиратства, полагает человек, знакомый с сотрудниками Apple: в те годы еще работал, например, скандальный allofmp3.com.
У Apple были прекрасные шансы выйти на российский рынок с iTunes в 2008 г., когда здесь только начались продажи iPhone, говорит Евгений Бутман, совладелец Ideas4retail и бывший акционер ECS Group (дистрибутор и розничный продавец техники Apple). Теперь ей придется отвоевывать место в плотной конкурентной среде и в гораздо более сложных условиях, предупреждает он. Высокая конкуренция не проблема, возражает руководитель сервиса «Яндекс.Музыка» Константин Воронцов: игроков на рынке легальной музыки в рунете чем дальше, тем меньше, и все они делают общее дело — формируют у пользователей неприятие пиратского контента. Приход iTunes только поможет развитию рынка, уверен он.
Чтобы занять значительную долю рынка в продажах музыки в рунете, Apple придется договориться с владельцами прав на отечественную музыку — самую популярную в стране, предупреждает сотрудник крупного западного мейджора. Воронцов подтверждает: хотя из почти 4 млн треков на «Яндекс.Музыка» российских всего около 50 000, на них приходится примерно 50% прослушиваний. Помимо правообладателей Apple ведет переговоры с онлайн-магазином Muz.ru (входит в группу ИФД «Капитал») о доступе к его музыкальной библиотеке, знает источник, близкий к одному из правообладателей. Представитель Muz.ru это не комментирует.
По данным Lenta.ru^
Аналогичная ситуация сложилась и с Google Play – магазином контента для устройств на базе Android. Россияне могут загружать оттуда только приложения; разделы с книгами, музыкой и видео для них пока закрыты.
Удивительная вещь: либо в Apple (и в Google?) сидят 100% идиоты (как они в этом случае столь успешно работают?), которые не понимают, что отказ от легальных продаж – поддержка нелегальных каналов доступа, либо (думаю, что сие вероятнее) “местные” (штатовские) правообладатели, запуганные россказнями о “злобных российских пиратах”, не даю разрешения на легальную продажу своего контента в РФ. А Российские правообладатели (узнав про то, что кто-то хочет торговать их контентом) “заламывают” непомерную цену и неприемлемые условия.
Снова Копирайт встаёт на пути легального потребления контента (слушания музыки, просмотра видео, чтения е-книг). Возникает вопрос: КТО ЗАИНТЕРЕСОВАН ЧИНИТЬ ТАКИЕ ПОМЕХИ? Понятно, что такой подход не выгоден экономике России (нелегальный доступ к контенту, превалирующий над легальным – дурной фон для развития экономики). Понятно, что такой подход не выгоден правообладателям (зачем поощрять нелегальный доступ, запрещая легальный?). Так КОМУ, всё-таки, такое “цензурировано” нужно?
Комментарии к записи Снова Копирайт против ЛЕГАЛЬНОГО потребления контента отключены
Открытым письмом как серпом…
Опубликовано 5 сентября 2012
Традиционный (для российского копирайтного лобби) способ борьбы с потребностями общества по обеспечению права граждан на доступ к информации – открытое письмо президенту.
Граждане и те, кто обслуживает их информационные потребности, идут нормальным законным путём: готовят законопроект и законопроект попадает на обсуждение в парламент. Специалисты начинают обсуждать (вот последнее из известных мне обсуждений – опубликовано на сайте “Университетская книга” 3 сентября 2012) и становится понятно, что потребности общества “похерить” в гласном обсуждении профессионалов не удастся.
И тут (как в анекдоте “Серпом по …”) копирайтное лобби переходит к непарламентским методам борьбы: отправляют первому лицу открытое письмо и начинают пропагандистскую компанию, пытаясь непарламентскими методами оказать давление на исполнительную власть дабы она выхолостила проект, чтобы он издателям не мешал и дальше гробить контентное обеспечение экономики.
Перед выборами (и до получения бумаг, подтверждающими вступление в ВТО) сложно было ожидать, что исполнительная власть пойдёт на открытое противостояние с копирайтным лобби. Но теперь выборы прошли, в ВТО Россия вступила (и не выгонят нас оттуда за то, что наше копирайтное законодательство приблизится к законодательству США и ЕС, которые обеспечивают библиотекам возможность обслуживать информационные потребности граждан е-книгами и в режиме ЧЗ и в режиме абонемента).
В думе первое чтение прошёл законопроект, который обеспечивает библиотекам принципиальную возможность обслуживания информационных потребностей граждан хотя бы в образовательной и научной литературе. Проект, конечно, удивительно напоминает советский метод вырезания аденоидов из анекдота (через задний проход автогеном), но сие – лучше чем ничего. На мой взгляд ТАКОЕ (отнюдь не оптимальное) решение – прямой результат многолетнего саботажа копирайтным лобби данной проблемы…Эдакое воздаяние копирастам за затягивание решения перезревшей проблемы…
Не думал я, что теперь снова появится открытое письмо президенту. Однако в сентябрьском номере “Университетской книги” снова появилось (ОТКРЫТОЕ ПИСЬМО-ОБРАЩЕНИЕ ИЗДАТЕЛЕЙ К ПРЕЗИДЕНТУ РФ ПУТИНУ В.В.). Текст письма короток и я рискну процитировать его целиком:
Президенту Российской Федерации Путину В.В.
Уважаемый Владимир Владимирович!
27 апреля 2012 года Государственной Думой принят в первом чтении законопроект № 47538-6 «О внесении изменений в части I, II, III и IV Гражданского кодекса РФ, а также в отдельные законодательные акты Российской Федерации». В части IV (Авторское право) предложена новая редакция статьи 1275.
Казалось бы, речь идет об очень локальной проблеме — о предоставлении библиотекам возможности безвозмездно создавать и использовать цифровые копии «произведений, имеющих исключительно научное и образовательное значение». Красивое решение: науку и образование — народу! Бесплатно! Вопрос один — за чей счет?
Фактически речь идет об отмене имущественных прав авторов и издателей учебной и научной литературы. Именно за их счет в случае принятия нового закона читатель получит бесплатные электронные книги. То есть речь идет об узаконенном интеллектуальном пиратстве, ведь библиотекам хотят дать право, ничего не платя, пользоваться результатами чужого труда и передавать это право кому угодно через межбиблиотечный обмен и «виртуальные читальные залы».
К чему это приведет?
К резкой девальвации самой интеллектуальной собственности.
К нежеланию ученых и преподавателей вузов готовить для издания новые учебники и научные труды.
К реальному и очень скорому исчезновению самой отрасли научного и учебного книгоиздания.
К появлению тысяч высококвалифицированных безработных.
Самое страшное, что здесь нет преувеличения!
Хотя вполне возможно, что авторы предложенных изменений руководствовались исключительно благими намерениями. Но это как раз тот случай, когда благими намерениями вымощена дорога известно куда…
Владимир Владимирович, мы обращаемся к Вам и как к гаранту Конституции, и как к человеку и гражданину, которому в первую очередь небезразлична судьба нашей страны, обращаемся с надеждой остановить принятие недопустимых, преступных поправок!
Вариант статьи 1275 части IV ГК РФ, разработанный совместно опытными юристами и ведущими специалистами нашей отрасли, прикладываем к данному письму.
Метод привычный – пугать тяжёлыми последствиями. Давайте посмотрим то самое приложение, где сравнивается действующее законодательство, проект (прошедший первое чтение) и альтернативный проект издателей. которые “от щедрот” разрешают оцифровку книг, образовательной и научной тематики, которые не переиздавались ДВАДЦАТЬ лет. Понятно, что и это больше, чем у библиотек есть сейчас и, в частности, решает проблему книг-сирот (у кого копирайт неизвестно и не переиздаются, а до истечения копирайта ещё 70 лет после смерти последнего из авторов…) . Итак:
Пояснительная записка к поправкам в законопроект N47538-6
Предлагаются две поправки в проект изменений 4 части Гражданского Кодекса Российской Федерации в части свободного использования произведения библиотеками, архивами и образовательными организациями (статья 1275).
Данные поправки направлены на сохранение баланса общественных интересов между авторами и издателями учебной и научной литературы с одной стороны и пользователями библиотек с другой.
Первая поправка предлагает уточнить круг произведений, в отношении которых допускается свободное воспроизведение общедоступными библиотеками. Законопроект предлагает разрешить библиотекам создание электронных копий “произведений, имеющих исключительно научное и образовательное значение”. Однако практика показывает, что практически любое произведение может быть отнесено к той или иной науке, и уж тем более к обучению. Поэтому предлагается разрешить оцифровку только редких книг, давно не выпускавшихся издателями (не переиздававшихся двадцать и более лет).
Вторая поправка предлагает сохранить действующий сегодня запрет библиотекам выдавать электронные копии произведений читателям.
В настоящий момент библиотеки имеют возможность изготавливать электронные копии произведений исключительно для целей межбиблиотечного обмена без права передачи файлов своим читателям. Законопроект допускает “предоставление копий, в том числе в электронной форме … по запросам граждан для научных и образовательных целей”. В случае принятия законопроекта в существующем виде библиотеки легализуют считающееся сегодня контрафактным распространение файлов произведений авторов без выплаты вознаграждения авторам. Издатели не получат вознаграждения от продажи книг, авторы не получат вознаграждения от издателей, пропадет экономическая мотивация создания авторами произведений. Это приведет к девальвации авторского труда и нарушит баланс интересов.
Принятие предлагаемых поправок не потребует дополнительного финансирования.
Действующая редакция
Статья 1275. Свободное использование произведения путем репродуцирования
1. Допускается без согласия автора или иного правообладателя и без выплаты вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования репродуцирование (подпункт 4 пункта 1 статьи 1273) в единственном экземпляре без извлечения прибыли:
1) правомерно опубликованного произведения – библиотеками и архивами для восстановления, замены утраченных или испорченных экземпляров произведения и для предоставления экземпляров произведения другим библиотекам, утратившим их по каким-либо причинам из своих фондов;
2) отдельных статей и малообъемных произведений, правомерно опубликованных в сборниках, газетах и других периодических изданиях, коротких отрывков из правомерно опубликованных письменных произведений (с иллюстрациями или без иллюстраций) – библиотеками и архивами по запросам граждан для использования в учебных или научных целях, а также образовательными учреждениями для аудиторных занятий.
2. Под репродуцированием (репрографическим воспроизведением) понимается факсимильное воспроизведение произведения с помощью любых технических средств, осуществляемое не в целях издания. Репродуцирование не включает воспроизведение произведения или хранение его копий в электронной (в том числе в цифровой), оптической или иной машиночитаемой форме, кроме случаев создания с помощью технических средств временных копий, предназначенных для осуществления репродуцирования.
Редакция законопроекта № 47538-6
Статья 1275. Свободное использование произведения библиотеками, архивами и образовательными организациями
1. Общедоступные библиотеки, а также архивы, доступ к архивным документам которых не ограничен, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения предоставлять во временное безвозмездное пользование (в том числе в порядке взаимного использования библиотечных ресурсов) оригиналы или экземпляры произведений, правомерно введенные в гражданский оборот.
При этом экземпляры произведений, выраженные в электронной форме, могут предоставляться во временное безвозмездное пользование (в том числе в порядке взаимного использования библиотечных ресурсов) только в помещении библиотеки или архива при условии исключения возможности дальнейшего создания электронных копий произведения.
2. Общедоступные библиотеки, а также архивы, доступ к архивным документам которых не ограничен, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать единичные копии, в том числе в электронной форме, экземпляров произведений, правомерно введенных в гражданский оборот:
1) в целях обеспечения сохранности и доступности для пользователей:
ветхих, изношенных, испорченных, дефектных экземпляров произведений;
единичных и (или) редких экземпляров произведений, рукописей, выдача которых пользователям может привести к их утрате, порче или уничтожению;
экземпляров произведений, записанных на машиночитаемых носителях, для пользования которыми отсутствуют необходимые средства;
экземпляров произведений, имеющих исключительно научное и образовательное значение;
2) в целях восстановления, замены утраченных или испорченных экземпляров произведения, а также для предоставления экземпляров произведения другим общедоступным библиотекам или архивам, доступ к архивным документам которых не ограничен, утратившим их по каким-либо причинам из своих фондов.
3. Библиотеки, получающие экземпляры диссертаций в соответствии с законом об обязательном экземпляре документов, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать единичные копии таких диссертаций, в том числе в электронной форме, в целях, предусмотренных пунктом 2 настоящей статьи.
4. Общедоступные библиотеки, а также архивы, доступ к архивным документам которых не ограничен, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать в единственном экземпляре и предоставлять копии, в том числе в электронной форме, отдельных статей и малообъемных произведений, правомерно опубликованных в сборниках, газетах и других периодических печатных изданиях, коротких отрывков из иных правомерно опубликованных письменных произведений (с иллюстрациями или без иллюстраций) по запросам граждан для научных и образовательных целей.
5. Образовательные организации при условии отсутствия цели извлечения прибыли вправе без согласия автора и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать копии, в том числе в электронной форме, отдельных статей и малообъемных произведений, правомерно опубликованных в сборниках, газетах и других периодических печатных изданиях, коротких отрывков из иных правомерно опубликованных письменных произведений (с иллюстрациями или без иллюстраций) и предоставлять их учащимся и преподавателям для проведения экзаменов, аудиторных занятий и домашней подготовки в необходимых для этого количествах.
6. Государственные архивы в рамках своей компетенции вправе создавать единичные копии произведений, размещенных в сети Интернет для хранения в архиве с исключением последующего воспроизведения и доведения до всеобщего сведения.”
Предложения издателей:
Статья 1275. Свободное использование произведения библиотеками, архивами и образовательными организациями
1. Общедоступные библиотеки, а также архивы, доступ к архивным документам которых не ограничен, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения предоставлять во временное безвозмездное пользование (в том числе в порядке взаимного использования библиотечных ресурсов) оригиналы или экземпляры произведений, правомерно введенные в гражданский оборот.
При этом экземпляры произведений, выраженные в электронной форме, могут предоставляться во временное безвозмездное пользование только в помещении библиотеки или архива при условии исключения возможности дальнейшего создания электронных копий произведения.
2. Общедоступные библиотеки, а также архивы, доступ к архивным документам которых не ограничен, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать единичные копии, в том числе в электронной форме, экземпляров произведений, правомерно введенных в гражданский оборот:
1) в целях обеспечения сохранности и доступности для пользователей:
– ветхих, изношенных, испорченных, дефектных экземпляров произведений;
– единичных и (или) редких экземпляров произведений, рукописей, выдача которых пользователям может привести к их утрате, порче или уничтожению;
– экземпляров произведений, записанных на машиночитаемых носителях, для пользования которыми отсутствуют необходимые средства;
– экземпляров произведений, имеющих исключительно научное и образовательное значение, не переиздававшихся двадцать и более лет с даты выхода в свет их последнего опубликованного издания на территории Российской Федерации;
2) в целях восстановления, замены утраченных или испорченных экземпляров произведения, а также для предоставления экземпляров произведения другим общедоступным библиотекам или архивам, доступ к архивным документам которых не ограничен, утратившим их по каким-либо причинам из своих фондов.
3. Библиотеки, получающие экземпляры диссертаций в соответствии с законом об обязательном экземпляре документов, при условии отсутствия цели извлечения прибыли вправе без согласия автора или иного правообладателя и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать единичные копии таких диссертаций, в том числе в электронной форме, в целях, предусмотренных пунктом 2 настоящей статьи.
4. Исключить
5. Образовательные организации при условии отсутствия цели извлечения прибыли вправе без согласия автора и без выплаты авторского вознаграждения, но с обязательным указанием имени автора, произведение которого используется, и источника заимствования создавать копии, в том числе в электронной форме, отдельных статей и малообъемных произведений, правомерно опубликованных в сборниках, газетах и других периодических печатных изданиях, коротких отрывков из иных правомерно опубликованных письменных произведений (с иллюстрациями или без иллюстраций) и предоставлять их учащимся и преподавателям для проведения экзаменов, аудиторных занятий и домашней подготовки в необходимых для этого количествах.
6. Государственные архивы в рамках своей компетенции вправе создавать единичные копии произведений, размещенных в сети Интернет, для хранения в архиве с исключением последующего воспроизведения и доведения до всеобщего сведения.
Собственно всё очень похоже. Отличия я выделил цветом и рискну процитировать комментарии по поводу этих отличий:
Под флагом уточнения понятия образовательных и научных произведений производится подмена понятия (с тематики на срок последнего переиздания). Обожаю профессионалов “передёргивания” (цитирую):
Предлагается дополнить абзац пятый пункта 1 новой редакции статьи 1275 Гражданского кодекса Российской Федерации в целях уточнения круга произведений, в отношении которых допускается свободное воспроизведение общедоступными библиотеками, путем введения дополнительных условий свободного использования в виде отсутствия переизданий на протяжении длительного времени, во избежание неоднозначного толкования понятия произведения, имеющего исключительно научное и образовательное значение.
И, чтобы убрать канал предоставления доступа к информации в цифровой форме предлагается (цитирую):
Предлагается исключить четвертый пункт статьи 1275 как противоречащий пункту 2 статьи 1274. Предоставление читателям электронных копий произведений приведет к нарушению баланса общественных интересов.
Пункт 2 статьи 1274 звучит так:
2. В случае, когда библиотека предоставляет экземпляры произведений, правомерно введенные в гражданский оборот, во временное безвозмездное пользование, такое пользование допускается без согласия автора или иного правообладателя и без выплаты вознаграждения. При этом выраженные в цифровой форме экземпляры произведений, предоставляемые библиотеками во временное безвозмездное пользование, в том числе в порядке взаимного использования библиотечных ресурсов, могут предоставляться только в помещениях библиотек при условии исключения возможности создать копии этих произведений в цифровой форме.
Не помню как звучит статья 1274 в законопроекте, но сохранение старой редакции статьи 1274 и пункта 4 новой статьи 1275 позволяет хотя бы частично снять ограничения на возможность “выноса из библиотеки” информации в цифровой форме (для курсовых, дипломов и исследовательских работ это крайне желательно – смешно в 3 тысячелетии переписывать с экрана дисплея. чтобы потом дома с переписанного с ошибками восстанавливать цитаты). Да, целиком вынести нельзя, но хоть цитаты и статьи можно сохранить в цифре. Издатели хотят воспрепятствовать и этому
Вывод:
Понятно, что в печатной форме укомплектовать десятки тысяч публичных библиотек книгами, которые издаются тиражами (хорошо если) 1-3 тысяч экземпляров невозможно. Ясно, что доступ возможен или “в цифре” или никак. Библиотеки ВУЗов (у которых ограничен профиль комплектования) могут позволить себе потратить немалые деньги в оплату за электронные библиотечные системы (и/или их фрагменты), которые будут интенсивно использоваться многими пользователями. У публичных библиотек ситуация сложнее. Спрос куда шире (т.е. заплатить за комплектование придётся очень много), а интенсивность использования весьма невелика. Действующие правила, требующие обязательного заключения письменного договора со всеми правообладателями е-книг, включаемых в коллекцию, препятствуют созданию больших коллекций. К тому же индивидуальные договора в любой момент могут привести к тому, что е-книга, которой пользуются много и интенсивно, внезапно исчезнет из доступа, поскольку срок старог договора истечёт, а нового может и не быть…
Принудительная оцифровка позволяет иметь коллекции актуальных е-книг (хотя бы определённой тематики). Если её ограничить сроком двадцать лет после последнего переиздания, то актуальных е-книг в публичных библиотеках не будет даже по образовательной и научной тематике.
Если запретить библиотекам выдачу на руки даже бы цитат и фрагментов в электронной форме, то говорить об эффективном обслуживании потребностей экономики силами публичных библиотек будет нельзя.
Т.о., предлагается ради продолжения беспрепятственного набивания карманов владельцами копирайта наплевать и на интересы экономики и на публичные библиотеки, как подотрасль культуры… То, что при этом появятся сотни тысяч интеллигентов, оставшихся без работы копирастов не волнует.
Хочется надеяться, что это волнует и власть и законодателей. Я не считаю, что обязательно применять именно тот вариант, который есть в законопроекте, который уже прошёл первое чтение. В нём уйма недостатков и единственное достоинство – он работоспособен. Если удастся БЫСТРО подготовить РАБОТОСПОСОБНЫЙ и ЭФФЕКТИВНЫЙ закон с меньшим объёмом недостатков, то почему бы и нет, а вот для саботажа время уже вышло. Закон надо принимать
Сверхдешёвый планшет TeXet на базе Android
Опубликовано 3 сентября 2012
Зоопарк ручных компьютеров сообщает, что появился (teXet TB-723А: ридер на ОС Android 4.0.3) – очередной бюджетный планшет-ридер (есть физические клавиши листания страниц) за 4300 рублей.

Данные (цитирую выборочно):
Устройство teXet TB-723А работает под управлением ОС Android 4.0.3 (Ice Cream Sandwich) на процессоре Boxchip A13 Cortex A8 с тактовой частотой 1,2 ГГц, оснащено 4 Гб встроенной памяти и слотом расширения microSDHC (карты объемом до 16 Гб). Оснащён 7-дюймовым экраном (разрешение 480 х 800 точек).
Pocketbook на IFA-2012
Опубликовано 3 сентября 2012
(IFA-2012) – крупнейшая выставка бытовой электроники (Берлин, 28 мая – 01 июня 2012) уже закрылась. По её результатам материал [email protected] (PocketBook на IFA 2012: пара новинок и впечатляющие прототипы)
Показали новый планшет, который не имеет физических клавиш листания и не позиционируется как ридер:

Это бюджетный 7-дюймовый планшет SURFpad на базе ОС Android 4.0.4 с большим комплектом предустановленных приложений и мультиформатностью. Установлены следующие приложения: браузер, почтовый клиент, аудиопроигрыватель, видеопроигрыватель, календарь, поиск Cool Reader, Office Suite Pro v.6, ArkMC, IM+, Learn English; и фирменные Obreey Diary, File Manager, Obreey Market и Obreey Store Shortcut.
Устройство поддерживает десять форматов видео – ASF, MKV, AVI, MP4, FLV, WEBM, 3GP, MOV, MPG, WMV, пять форматов аудио – MP3, WMA, AAC, OGG, MIDI, десять текстовых форматов: EPUB, PDF, FB2, FB2.ZIP, TXT, HTM, HTML, DOC, DOCX, RTF и четыре графических – JPEG, BMP, PNG, GIF.
SURFpad оснащен 7-дюймовым ЖК-экраном разрешением 800х480 (емкостным, мультисенсорным), процессором Cortex A8 на 1 ГГц, 512 Мбайт оперативной памяти, 4 Гбайт постоянной памяти, портом microUSB, слотом для microSD, 3,5-мм разъемом для наушников, встроенными динамиками, модулем Wi-Fi. Планшет отличается приятным дизайном, хотя на фотографиях он выглядит лучше, чем в реальности (сказывается примененный в оформлении недорогой пластик) и предлагается в трех цветовых вариациях: черный с серым, черный с белым и черный с красным. Весит он всего 285 грамм, обещают, что держит заряд в режиме просмотра видео примерно 6,5 часов. Все довольно простенько, но и цену обещают низкую – в районе $120-130.
Обновились обе простейшие читалки в ассортименте PocketBook — Basic (за счет исчезновения Wi-Fi модуля упадет цена — за новый Basic просят 4450 рублей) и Touch (вышла новая прошивка)
У PocketBook уже есть на руках образцы и HD-экрана на базе электронной бумаги с подсветкой (или надсветкой, как ее называет PocketBook), и цветного E-Ink экрана, опять же, с подсветкой. Но пока это всё прототипы…
PocketBook планируется уже в самое ближайшее время запустить сервис ReadRate, позволяющий обмениваться впечатлениями о прочитанных книгах в различных социальных сетях: приложение поддерживает Facebook, Вконтакте и Одноклассники. Будут встроены и обязательные в таком случае кнопки «Читаю», «Прочитал» и «Нравится» в меню управления чтением, система рекомендаций, будут показываться рецензии, встроена система поиска.
Взросление text 2.0
Опубликовано 30 августа 2012
text 2.0 (он же улучшенный текст, интерактивный текст и т.п.) взрослеет.
От детских сказочек для отработки технологии уверенно движемся к прозе для взрослых. У (iRevolution Ltd) от (Дюймовочка – интерактивная книга с играми) движемся к детективу (Ш. Холмс «Пестрая лента» HD). Честно говоря, ожидал, что “для взрослых” да ещё интерактивно будут что-нибудь эротическое использовать, но и из детектива 100 тыс. платных скачиваний (по $3 за штучку).
Версия доступна для iPad. но обещают и для iPhone


Есть и видеоролик:
Есть (данные) о сотрудничестве с французами:
Компания iRevolution совместно с французской компанией Byook выпустила локализованные версии интерактивных книг для iOS «Ш. Холмс — Пестрая лента» и «Ночной кошмар».
«Ночной кошмар» интересен, разве что, наличием версии для iPhone

