ЭБС в образовании
Опубликовано 20 декабря 2013

опубликовала 19.12.2013 (Российские ЭБС: мнение лидера рынка) – иннтервью, в котором участвовал Александр Владимирович НИКИФОРОВ, директор издательства «ЛАНЬ», и мнения экспертов. ради “завлекалочки” процитирую первый абзац:
В ноябрьском номере «УК» были представлены очередные результаты исследования «ЭБС в библиотеках: как это работает на практике», в котором приняли участие более 290 библиотек-респондентов из 46 регионов России. По итогам мониторинга в 2013 г. лидером рейтинга стала ЭБС издательства «ЛАНЬ». Мы обратились к представителям этого ресурса с предложением прокомментировать ситуацию, складывающуюся на рынке агрегации контента, оценить его перспективы развития и востребованность предлагаемых сервисов.
Материала подробный и интересный. Кому интересно – перейдите по ссылке и читайте
Комментарии к записи ЭБС в образовании отключены
Почтипланшеты приходится “ломать”
Опубликовано 28 января 2013
В посте от 25 января 2013 (Почти планшет PocketBook SurfPad) я говорил о сверхдешёвом почти планшете PocketBook SurfPad у которого “внутри” Android 4, но доступа к серьёзному репозитарию (например, к GooglePlay/AndroidMarket) и возможности установить нужное ПО нет. Такие устройства приходится “ломать”, дабы поставить полноценный Android с доступом к репозитарию.
Слава Баранский в паре статей объяснил почему такое приходится делать…
В первой статье (Как хранить книги в облаке с синхронизацией между устройствами при чтении) рассказывается об известном сервисе Bookmate как о средстве читать на всех устройствах (стационарных и мобильных), которые у человека есть (в т.ч. при своевременной синхронизации можно читать и в то время, когда Интернет недоступен).
Из мобильных ОС клиенты (спустя долгий период, когда их только обещали) доступны для:
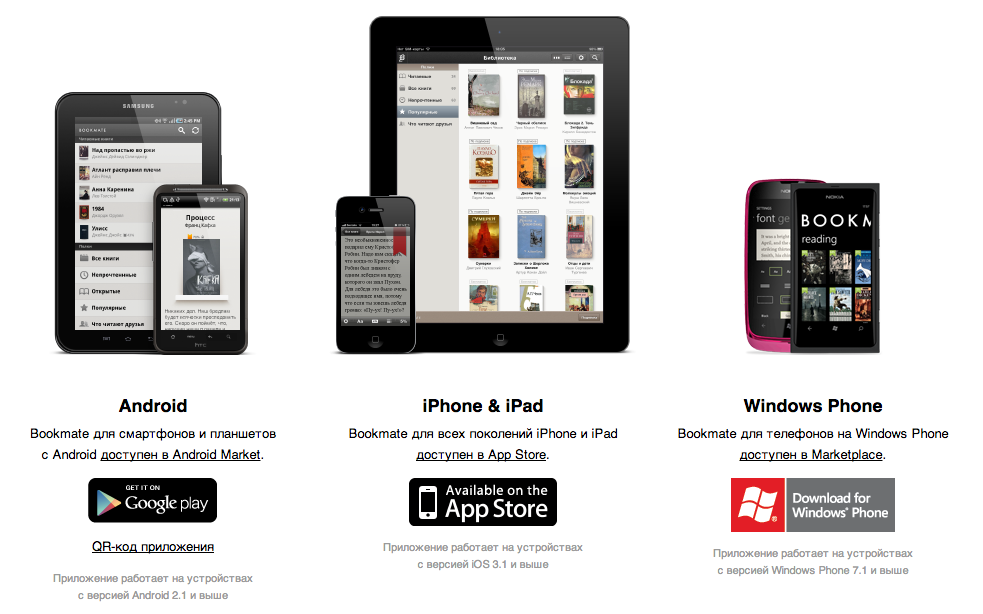
Во второй статье (Как читать книги Bookmate на книжной читалке NOOK) рассказывается зачем “ломать” устройство с Android внутри (цитирую выборочно):
Недавно мне попался девайс B&N NOOK Simple Touch стоимостью $79 — маленькая и легкая читалка с чувствительным к нажатиям экраном типа «электронные чернила», у которой на борту wi-fi и, самое главное!, полноценный Android, на котором резво бегает Bookmate 🙂 Идеально в одном месте сошлись звезды. И вот как это все работает.
Полноценным Android на этом почтипланшете становится ПОСЛЕ того, как его удастся ВЗЛОМАТЬ
Внутри устойства стоит одна из версий Android, но вы к ней не сможете получить доступ. Устройство при включении будет попадать в написанную оболочку и мало чем вообще будет выдавать в себе эту ОС. Установка более отзывчивого Андроида можно провести изучив внимательно ветку форума на 4PDA. После вы получите планшет на Android с ч/б экраном и чувствительным к прикосновениям экраном. На эту ОС установите Bookmate для Android. Затем вы сможете в нем читать книги с облачной синхронизацией новых книг, прочитанного прогресса, закладок и того, что читают ваши друзья.
Что касается шрифта, то наиболее мне понравился шрифт Charter.
!!!! В комментах уточнили адрес ветки форума
Классная мысль – получить планшет с полноценным Android и экраном e-ink. За очень невеликую цену получаем конвергентное устройство с экраном e-ink, которое вполне справляется с чтением и, если не обращать внимание на монохромность и некоторую “неторопливость” смены экрана (препятствует просмотру видео), вполне справляется с тем, что должен делать недорогой планшет на Android
интервью с Е. Милицей, ген. директором PocketBook Rus
Опубликовано 10 июля 2012
Пришёл, наконец, ответ на наши вопросы. Мы результат опубликуем на отраслевом портале Library.ru (ссылку сообщу). Чтобы легче было ждать – посмотрите (PocketBook: ответы на все вопросы) собранные [email protected]
Комментарии к записи интервью с Е. Милицей, ген. директором PocketBook Rus отключены
Американский опыт. Отчёт
Опубликовано 17 мая 2012
В дополнение к посту от 16 мая 2012 (Американский опыт), где анонсировалась встреча с создателями электронной библиотеки в Университете штата Вайоминг.
Доклад состоялся.Вот его заставка.

Надежд на информацию о решении копирайтных проблем встреча,к сожалению, не оправдала. Там (в библиотеке университета штата) оцифровали гербарий. Технологически это интересно, но копирайтных проблем нет. Коллекция принадлежит университету целиком и полностью, включая все и всяческие права и университет библиотеке дал добро. С краеведческой литературой проблем почти нет. Либо документы (в т.ч. старинные книги и карты) уже не подпадают под копирайтные ограничения, либо права принадлежат партнёрам Университета (например, краеведческий журнал дал добро на оцифровку своего архива с 1924 года, но кроме последних 5 лет, т.е. каждый год ещё год будут оцифровывать). Проблемы, как следствие, у них, в первую очередь, технологические (организация работы с данными и обеспечение их сохранности при облачном хранении десятков терабайт штука непростая…
Ещё один желающий жать там, где не сеял
Опубликовано 30 апреля 2012
В дополнение к моему посту от 08 октября 2011 (Авторское и патентное право, как способ «жать, где не сеял») о тенденции к появлению исков от копирастов с целью получать платежи с тех кто работает за якобы имеющиеся нарушения копирайтных или патентных прав. Последний пример – иск прокуратуры к производителям устройств, описанный в посте от 29 апреля 2012 (Наказали за то, чего не делали) о попытках наказать производителей за то, что с их устройствами могут сделать (а могут и не сделать) пользователи…
И вот – очередной пример. Компьютерра блоги сообщила. что (В Германии Youtube назначили ответственным за действия его пользователей). Суть попытки заработать проста. На основании решения суда о том, что Goofle ответственен за то, что на Youtube МОЖЕТ быть закачан (а может быть не закачан) защищённый копирайтом контент, некая организация по коллективному управлению правами в Германии (местное агентству по коллективному управлению правами и сбору авторских отчислений — GEMA.) требует Youtube/Google фиксированный процент с рекламных доходов – 10%.
Т.е. работает Google, а GEMA (только за то, что сервисы Google технически могут быть использованы для нарушения копирайта) хочет иметь “десятину”… По сравнению с их аппетитами наш Добрыня Никита с его 1% от цены устройств смотрится как гений доброты и милосердия
3M -это облако
Опубликовано 28 апреля 2012
По наводке из (коммента) от Александр с благодарностью сообщаю:
Engadget (3M launches its Cloud Library e-book lending service, hardware and apps in tow), а Mobi пересказал новость о том, что (3M запускает первую облачную библиотеку). Этот пересказ я процитирую целиком (материал – под катом):
Комментарии к записи 3M -это облако отключены
Осталась только “непечатная” Encyclopædia Britannica
Опубликовано 19 марта 2012
В “старые добрые” времена библиотекам предлагали печатную Encyclopædia Britannica, которая (в полном комплекте печатных томов) стоила от $1500. А CD-ROM-ная версия энциклопедии стоила “всего” $400 и было ясно, что полноценный компьютер с “непечатной” версией лицензионно чистой энциклопедии стоит дешевле, чем версия печатная… Правда, “на Горбушке” такой диск (позже два диска в одной упаковке) стоили 100-200 рублей, а копирайтных запретов на деятельность библиотек по обслуживанию информационных потребностей граждан было куда меньше, чем сейчас… Стоит ли удивляться, что у граждан популярностью пользовались пиратские версии энциклопедии, а у библиотек обычно покупались печатные версии – это было отличное “вложение в вечность” – печатная Британика была не менее “маст хэв”, чем факс и визитка у директора…
Надо сказать, что лицензионная электронная БСЭ стоила (если покупать в пластике, а не в картоне) раза в два дороже, чем пиратская и у граждан и библиотек хватало “запаса прочности”, чтобы покупать лицензионную, а не пиратскую версию.
Стоит ли удивляться, что Encyclopædia Britannica (CD-ROM версия энциклопедии в качестве программы-клиента изначально использовала браузер, хоть и модифицированный) быстренько перебралась в Интернет и стала доступна платно (поиск проводится бесплатно и представляются ссылки на найденное, НО… открываются полные ссылки только зарегистрированным пользователям).
И вот CNNMoney(Encyclopedia Britannica to stop printing books) опубликовал (ролик про энциклопедию) и сообщил печальную новость. Есть пересказ (Энциклопедия Britannica будет выходить только на цифровых носителях), который я процитирую целиком:
Издатели “Британники” (Encyclopædia Britannica) объявили об отказе от выпуска энциклопедии на бумажных носителях, сообщает Agence France-Presse во вторник, 13 марта. “Британника”, выходившая в течение 244 лет, станет “полностью цифровой”, говорится в заявлении, распространенном издателем энциклопедии – американской компанией Encyclopædia Britannica. “Это последний шаг в нашей эволюции от издательства, которым мы были, до создателя цифровых обучающих продуктов, которым мы являемся в настоящий момент”, – подчеркивается в заявлении Encyclopædia Britannica. Энциклопедия “Британника” – старейшая англоязычная универсальная энциклопедия, первый выпуск которой появился в 1768 году. С момента основания “Британники” по настоящее время вышло 15 “бумажных” многотомных изданий. Пик продаж “Британники” в США пришелся на 1990 год, когда в стране было продано 120 тысяч изданий энциклопедии в 32-х томах. Однако вскоре после этого продажи “Британники” резко снизились, в основном из-за широкого распространения интернета. Первая версия знаменитой энциклопедии на цифровых носителях была представлена еще в 1981 году, в 1989 году была выпущена мультимедиа-версия на CD , а в 1994 году “Британника” была выложена в Сеть. В настоящий момент, по данным Encyclopædia Britannica, онлайн-версией энциклопедии пользуется около 100 миллионов человек. При этом на долю онлайн-версии энциклопедии приходится лишь 15 процентов годовой выручки Encyclopædia Britannica, отмечает CNN, остальное приносят продажи различных обучающих продуктов, выпускаемых компаний. В 1997 году Encyclopædia Britannica уже объявляла о намерении полностью перейти на цифровые носители. Однако тогда от этой идеи было решено отказаться.
Теперь обнаруживается, что прикупить последнюю печатную версию издания мы опоздали. Жалко…
Премьера нового iPad
Опубликовано 8 марта 2012
Премьера нового iPad состоялась вчера (начало в 22 часа по Москве). Описание в Известиях (Компания Apple представила миру новый iPad) показало, что устройства с промежуточным экраном (между 3,5″ у iPodTouch/iPhone и 10″ у iPad) пока не было представлено. Цена у планшета осталась прежней. Чуть лучше стал экран, чуть шустрее процессор (4 ядра – не шутка). Но сегменты с экраном 4-5″ и 6-8″ по прежнему “провисают”… А что же есть (цитирую):
Новая версия знаменитого планшетника обладает процессором A5X с четырьмя графическими ядрами и экраном Retina с разрешением 2048 на 1536 точек. Насыщенность цвета увеличилась на 44%.
Камера компьютера имеет 5 мегапикселей и теперь способна записывать видео FullHD 1080p. Также в iPad появилась новая функция голосовой диктовки, которая, к сожалению, не поддерживает русский язык. Как и в сервисе Siri, распознаваться будут английский, французский, немецкий и японский языки.
Отныне устройство поддерживает сети четвертого поколения (LTE) и все существуюшие 3G сети. Толщина нового iPad составляет 9,4мм, вес – 635г. Время автономной работы от батареи – 10 часов (при использовании 4G-сетей – 9 часов).
Стоить компьютер будет $499 (16GB), $599 (32GB) и $699 (64GB) за Wi-Fi-модификацию и – $629, $729 и $829 соответственно за версию с поддержкой LTE-сетей. Предзаказ доступен с сегодняшнего дня в США, Канаде, Великобритании, Франции, Германии, Швейцарии и Японии
Не понял я, существуют ли версии нового iPad только с WiFi (цен тогда должно быть 6, а не 3). Понятно, что с появлением этого устройства возрастёт трафик и в сетях общего пользования и в мобильных сетях… Но, к сожалению, устройство втягивает индустрию в гонку технических характеристик. А, ведь, очень многим такие характеристики просто излишни
DeepApple (Apple представила iPad третьего поколения) опубликовал технические подробности
Есть (рядом) тактинка сравнения маделей ipad
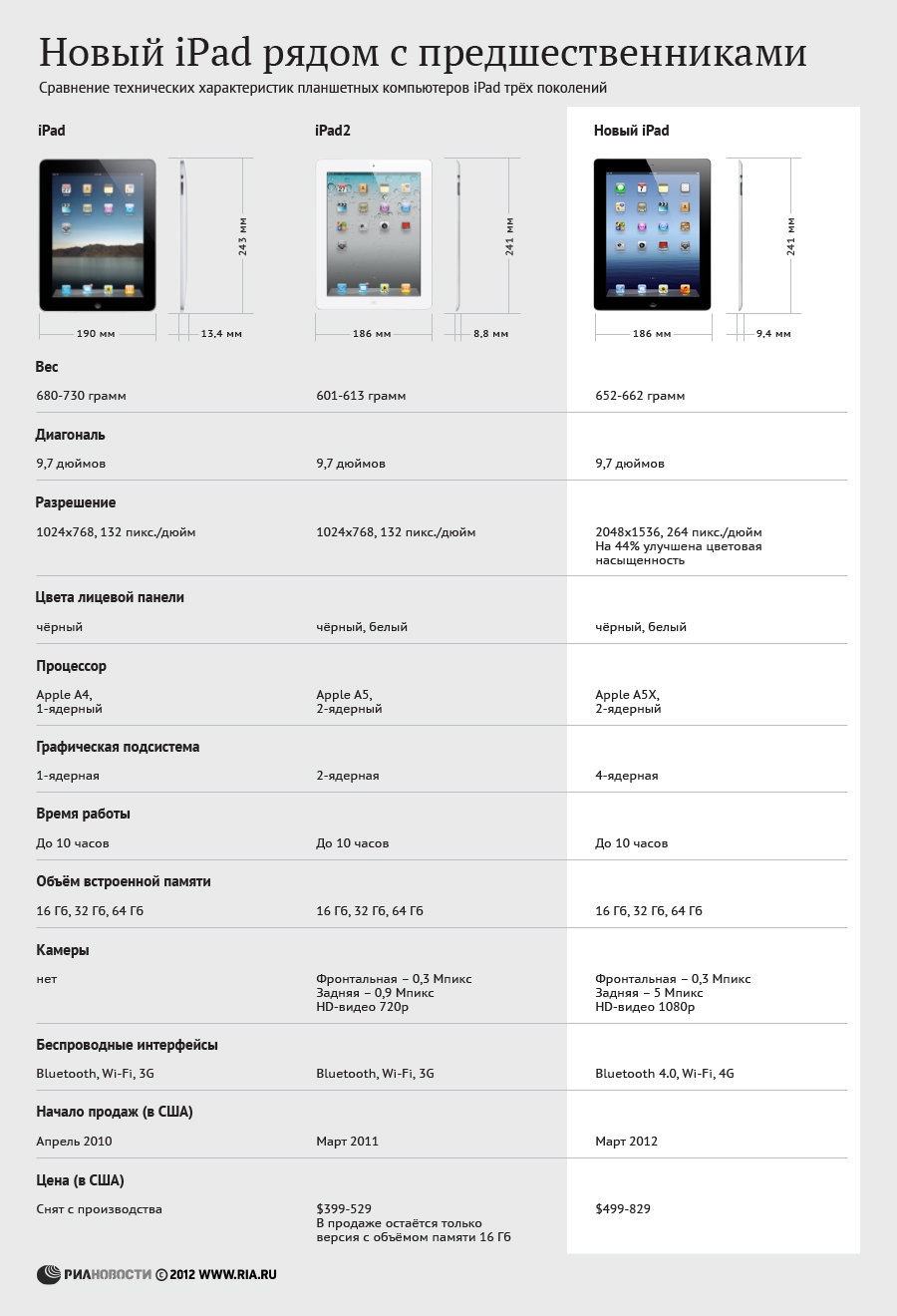
Щёлкните по иконке, чтобы получит картинку целиком
Gopal (Новый Apple iPad 3 – резолюционно!) привёл рекламный ролик нового iPad на русском и своё сравнение с предыдущей моделью…
Всё та же мысль: “Игрушка, конечно, красивая (и, возможно, кому-то ОЧЕНЬ понравится), но хотел-то я от них совсем другого…”
Закрытая презентация проекта колонизации
Опубликовано 29 февраля 2012
Google Books – это, как известно, открытый проект информационно-технологической колонизации. Понятно, что имея св. миллиона наименований бесплатных книг (пусть, в основном, на английском) можно смело “тянуть одеяло на себя” и перетаскивать авторов и издателей в “дядин” проект. Наш основной продавец легальных е-книг (Литрес) с его 65 тысячами наименований ничего противопоставить этой силе (за которой нехилое финансирование) не сможет. И станет “доминирующий Google” решать кому в России какие книги и на каких условиях читать…
Возможно, именно поэтому (ПРЕЗЕНТАЦИЯ СЕРВИСА ЭЛЕКТРОННЫЕ КНИГИ GOOGLE В МОСКВЕ. 29 февраля 2012 года) прошла в закрытом режиме. Есть фотография и официальное сообщение:

В Московском офисе Компании Google прошла презентация проекта Google eBooks, куда были приглашены руководители крупных российских издательств, в числе которых “Питер”, “Дрофа”, “Геотар”, “Мозаика”, а так же агрегаторов – “ЛитРес”, “Университетская библиотека онлайн”, Консорциум “Контекстум”. Мероприятие было закрытым, присутствовал ограниченный круг представителей отрасли. Презентацию проводили руководители международных партнерских программ компании Анна Ерёменко и Александр Брегман.
В процессе презентации собравшимся была показана работа сервиса Google Электронные книги, который успешно работает в Америке. Сервис предполагает продажу электронных копий книг и, конечно, чтение этих книг с помощью приложений, специально разработанных Google (Google Apps). Читать книги Google можно будет на любых устройствах, которые удобны пользователю: в веб-браузере компьютера, на приложении для планшета или смартфона, на ридере. В своем вступительном слове Владимир Долгов (генеральный директор Google Russia) рассказал, что 5 из 10 бестселлеров в Японии уже сегодня написаны (!) на мобильном телефоне. Google предлагает читать электронные книги как из облаков (компания является одним из мировых лидеров в сфере облачных технологий), так и оффлайн. “Облачное чтение” дает пользователю целый ряд преимуществ: сохранение настроек просмотра, заметок, и закладок книги вне зависимости от смены устройства, используемого для чтения.
В России старт сервиса Google Электронные книги запланирован на вторую половину 2012 года. В настоящий момент проходят подготовительные работы для запуска проекта, частью которых стало данное мероприятие. Его целья являлось предварительное знакомство представителей издательского рынка России с проектом.
Компания Google не только предоставляет пользователям по всему миру лучшую поисковую систему, но также является крупнейшим агрегатором цифрового контента в рамках своего проекта GoogleBooks. Таким образом российские издатели получают уникальную возможность выхода на мировой рынок в партнерстве с Google.
Вот такой-вот текст из которого можно узнать только то, что проект – это круто и начнётся во второй половине 2012. Есть кое-какие подробности в твиттер-трансляции (цитирую выборочно):
- Когда вы говорите я лучше, чем Google, будьте уверены, что сможете это доказать
- 2/3 россиян готовы платить больше за лучшие продукты и сервисы
- издатель рекомендует цену, но реселлер продаёт за сколько хочет, но процент издатель получает от рекомендованной цены #Александр Брегман
- Пользователь может купить книгу любой страны, издатель может продать книгу по всему земному шару #Александр Брегман
- Размер магазина в америке – 3млн книг, 7тыс. издателей, прочитано около 1,5 миллиарда страниц #Александр Брегман
- В сша в конце 2010, в ближайшие 2 месяца Европа, до конца года – Россия
- Файлы имеют DRM защиту, можно скачивать на ридер и читать на устройстве где нет интернета #Александр Брегман
- Мы можем менять размер, шрифт, подсветку, читать офлайн или онлайн, в браузере, на телефоне, и на планшете #Александр Брегман
- Предпросмотр в электронной книге – первые 10% книги #googleebookstore
- Кто создаст дополнительные сервисы, тот будет популярнее #Сергей Анурьев(ЛитРес)
- Через 5 лет электронная книга сможет занять 20, 25, даже 50% рынка книг #Сергей Анурьев(ЛитРес)
- Российский рынок b2c растёт в 2 раза в год, сейчас – 5млн$ #Сергей Анурьев(ЛитРес)
К сожалению видеотрансляцией не озаботились…
Из того, что сказал Анурьев. $5 миллионов – это 150 млн. руб. Если среднюю цену продаж взять 50 руб/е-книга, то сие соответствует 3 млн. продаж в год. Это, конечно, больше, чем ничего, но ненамного… Ясно, что миллионеров (авторов, у которых есть миллион и более платных скачиваний) у Литрес (и/или других продавцов) ещё долгонько не будет
Что до обещания 20% рынка через 5 лет…
2010 – 0,1% При удвоении:
2011- 0,2%
2012 -0,4%
2013 – 0,8%
2014 – 1,6%
2015- 3,2%
2016- 6,4%
2017-12,8%
2018-25,6%
Прогноз, конечно, сильно оптимистичный и предполагает, что годовое удвоение удастся сохранить на длительный период… Хотя, конечно, если рынок печатной книги продолжит “схлопываться” темпом 6-8% в год, то резко уменьшится рынок в целом и 20% доля уменьшившегося рынка за 5 лет может оказаться вполне достижимой
____________________________
Вот вариант описания презентации от Pro-books (цитирую целиком):
29 февраля в Москве состоялась встреча представителей компании Google с российскими издателями и книготорговцами. Ее темой стал предстоящий запуск Google Books и Google eBooks в России.
Как сообщает ресурс Руконт, во встрече, прошедшей в гостинице «Балчуг», участвовали руководители крупных российских издательств, в числе которых «Питер», «Дрофа», «Геотар», «Мозаика», а также агрегаторов – «ЛитРес», «Университетская библиотека онлайн», Консорциум «Контекстум».
Представители компании Google Анна Еременко и Александр Бергман продемонстрировали им сервис Google eBooks, предполагающий продажу и чтение электронных книг с помощью приложений, разработанных Google. Читать книги с помощью сервиса можно будет на компьютере, планшете, смартфоне или ридере, причем как из «облаков», что позволяет пользователям сохранять настройки просмотра, делать закладки и заметки, так и в оффлайн-режиме.
Владимир Долгов, генеральный директор Google Russia, заявил, что поддержка отечественных книгоиздателей для Google просто необходима, иначе инициативы компании в области продажи электронных книг в России не смогут получить продолжения.
«Наш мир меняется, и вы всё это видите. Мобильные устройства за последние двадцать пять лет развивались совершенно немыслимыми темпами, и сегодня в мире у людей на руках находится примерно пять миллиардов мобильных телефонов. Причем, чтобы достичь пятого миллиарда, понадобилось всего девять-десять месяцев», — сообщил Владимир Долгов, подчеркивая, что электронные средства для чтения стали вездесущими, а сам способ чтения кардинально меняется.
Встреча в «Балчуге» была ознакомительной — ни к каким конкретным договоренностям стороны пока не пришли, однако общение оказалось интересным и для Google, и для специалистов книжной отрасли.
В качестве приглашенного эксперта на встрече выступил Сергей Анурьев, глава интернет-магазина электронных книг «ЛитРес». Он заявил, что розничный рынок продаж электронных книг в России удваивается каждый год, на 2011 год его обороты составили около 5 млн долларов. «Если он будет расти дальше и преодолеет ныне существующие барьеры — такие, как пиратство, отсутствие связанных устройств продаж контента, – он может вырасти в ближайшие годы в два, три, а то и в десять раз», — обнадежил собравшихся Анурьев.
Напомним, что заняться развитием сервиса электронных книга в России Google пытается не первый год. Еще в 2009 году компания запустила российскую версию библиотеки Google и проект «Поиск по книгам Google».
Старт сервиса Google Электронные книги в России намечен на вторую половину 2012 года. Сейчас компания активно готовится к его запуску.
Понятно, что без российских правообладателей (а это, в основном, издатели) сервису не обойтись, но я как-то плохо понимаю, станут ли российские правообладатели отдавать контент Google, если они его не продают легально через другие каналы. А отсутствие занчительной части изданного в печатном виде контента в легальном доступе “в цифре” означает неминуемое пиратство. Наши магазины будут стенать и объяснять, а вот Goodle (за спиной у которого сила, способная проявить “заботу о праве Российских граждан на доступ к информации”; правда информация будет отбираться этой “силой” в собственных интересах) вполне способен на “резкие движения”. Организовать в США сервер по торговле принудительно оцифрованными книгами на русском (конечно, в порядке “заботы о правах российских граждан”) и задавить российскую книготорговлю, которая вынуждена соблюдать российское копирайтное законодательство вполне можно. У Google на это хватит средств и квалифицированного персонала, а у правительства США вполне хватит сил, чтобы поддержать подобный проект, например, в качестве санкции против России за “неправильное” голосование в Совете безопасности…
Очень не хочется. чтобы подобные сценарии стали реальностью.
___________________
Ещё описание от Компьютерра (Google займётся электронными книгами в России). Поскольку есть очень интересные моменты, то рискну и его процитировать целиком:
Автор: Юрий Ильин
Опубликовано 29.02.2012 в блоге автора (rss)
Google собирается запускать проект Google Books в России, и сегодня в гостинице «Балчуг» прошло мероприятие, связанное с этим скорым событием. В России проекты Google Books и Google eBooks будут фигурировать под названиями «Google Книги» и «Google Электронные книги» соответственно (второе касается торговли электронными изданиями). Эта тема для России пока ещё относительно нова, а потому ситуация на рынке книгоиздания, включая электронное, сейчас очень шаткая. С одной стороны, катастрофически падают тиражи, особенно художественной литературы не самого массового толка. С другой стороны, традиционные книгоиздатели не слишком охотно доверяются электронной книготорговле, и на то у них масса причин (пиратство — первая среди них).
У Google, с точки зрения издателей, есть одно очень существенное достоинство: это бренд. Такой компании совершенно не за чем пускаться в какие-то нечистоплотные авантюры (когда, например, электронный книгоиздатель А подписывает с компанией Б договор о «защищённом» издании текстов в электронном виде, а затем, спустя несколько месяцев, вздыхая, констатирует, что их DRM плохо работает или не работает вообще).
Неудивительно, что собравшиеся на мероприятие (а это преимущественно были именно книгоиздатели и книготорговцы) засыпали представителей Google вопросами, так что даже на перерыв времени не осталось. Со стороны Google шли преимущественно подробные объяснения, что потребуется с издателей, если те захотят сотрудничать. Издатели, в свою очередь, старались выяснить, что им за это будет и насколько легко или сложно станет «украсть» их книги. Например, через поиск бесплатно доступно 20 процентов контента продаваемой электронной книги; одна из участниц мероприятия дознавалась, возможно ли так сформулировать запросы, чтобы доступными — с разных IP — стали все 100 процентов? На это ей было резонно замечено, что дешевле книгу элементарно купить, нежели идти на такие ухищрения.
У Google, безусловно, свой интерес: на встрече несколько раз прозвучало, что без поддержки российских книгоиздателей «Google Книги» запустить не удастся, особенно коммерческую его составляющую.
«Наш мир меняется, и вы всё это видите. То устройство, а иногда и два, и три, которые есть у всех у вас в кармане и которые называются „мобильными телефонами“… за последние двадцать пять лет развивались совершенно немыслимыми темпами. Сегодня в мире у людей на руках находится примерно пять миллиардов мобильных телефонов. Первый миллиард набрался за двадцать лет истории этого прибора, второй — за четыре года, третий — за два, четвёртый — за один, а пятому понадобилось всего девять-десять месяцев», — заявил Владимир Долгов, генеральный директор Google Russia (бывший, кстати, генеральный директор книжного интернет-магазина Ozon).
Всю эту статистику он привёл главным образом для того, чтобы показать, что теперь электронные средства для чтения (смартфоны к ним, безусловно, тоже относятся) стали вездесущими, и соответствующим образом изменился подход к чтению. И к авторству тоже:
«Япония, при том что она — страна гаджетная, до сих пор продолжает читать. Там книга считается бестселлером, если она достигает планки тиража (я говорю о физических книгах) в 400 тысяч. Можно сравнить это с Россией и понять, кто из нас „читающая страна“ — Россия или Япония. Так вот, пять из десяти бестселлеров их авторы написали на своих мобильных телефонах. Верьте, нет, но это так. Это вот прямое влияние мобильных телефонов и смартфонов на индустрию, о которой мы говорим», — заявил Долгов.
В дальнейшем на мероприятии, однако, прозвучало, что никто не может дать никаких гарантий, что электронные читалки полностью вытеснят традиционные книги. Причём сказал это лично Сергей Анурьев, глава компании «ЛитРес», занимающейся как раз-таки электронным книгоизданием.
В ходе своего выступления Анурьев, приглашённый Google в качестве эксперта, заявил, что розничный рынок продаж электронных книг в России удваивается каждый год, но на 2011 года обороты его составили около 5 млн долларов. «Если он будет расти дальше и преодолеет ныне существующие барьеры — такие, как пиратство, отсутствие связанных устройств продаж контента, он может вырасти в ближайшие годы в два, три, а то и в десять раз», — заявил Анурьев.
При этом Сергей Анурьев указал, что отрасль беспокоит один вопрос: является ли электронная книга нишевым продуктом для людей, которые любят гаджеты и всё, что с ними связано, или она превратится в настоящую «замену» бумажной книги.
«Этот прогноз невозможно сделать. Так же, как лет десять назад обсуждался вопрос, как аудиокнига повлияет на рынок бумажной книги, так же точно сейчас обсуждается, будет ли электронная книга нишевой или нет. Это будет видно на рубеже десяти лет. На рубеже пяти лет мы можем прогнозировать, что электронная книга легко может может занять и 25, и 50 процентов книжного рынка», — заявил Анурьев.
В ходе презентации представителей Google между делом спросили: а удалось ли им посотрудничать с российскими библиотеками? Как выяснилось, Google ставит на книгоиздателей в большой степени «не от хорошей жизни». По словам выступавших, традиционные культурные учреждения склонны проявлять консерватизм и с некоторым недоверием относиться к предложениям Google. Русскоязычные книги в Google Books представлены, однако преимущественные их источники — зарубежные библиотеки.
«У нас были переговоры с российскими библиотеками, но никаких проектов из этого не вышло, к сожалению», — отметила Анна Ерёменко (Google Books).
«Мы очень долго общались [с Российской Государственной Библиотекой], — пояснил Александр Брегман, — и продолжаем общаться, но эти разговоры идут очень долго и, видимо, ещё продолжатся». Иными словами, пока договориться не удалось.
Помимо презентации проекта Google Книги, книгоиздателям в течение часа демонстрировали достоинства платформы Android и связанных с ней инноваций. Судя по всему, Google намеревается всеми силами поддерживать в России связку «Android — электронные книги».
Понятно, что в библиотеках есть всё (почти всё), что может быть издано в цифре, но именно такая возможность меня и тревожит. Российские магазины права продавать всё это заведомо не получат, т.е. Google будет иметь очень большое рыночное преимущество и (благодаря ему) сможет задавить российскую торговлю легальным контентом…
Интересно для сравнения почитать интервью с Анурьевым 2010 года (Сергей Анурьев (“ЛитРес”) об электронном книгоиздании: Глава магазина электронных книг “ЛитРес” изложил “Компьютерре” свою точку зрения на перспективы электронных книг и сосуществование электронного и традиционного книгоиздания.). Время прошло и ритуальные “взвизги” про злобных пиратов уже не мешают пониманию того, что основное средство борьбы с пиратами – сервис и ассортимент продаваемых е-книг. И видно сие уже и по реальной политике Литрес и по высказываниям его директора
Копирасты против Масяни
Опубликовано 19 февраля 2012
Самое страшное для копирастов – готовность автора отдать результат своего труда БЕСПЛАТНО. Вот решил создатель Масяни (и владелец авторских прав на мульты с ним) выложить свои творения для всеобщего и бесплатного доступа в YouTube…

И вот как об этом рассказывает PiratMedia (Очередной апофеоз копирастии):
Олег Куваев: «Your video, Масяня. Эпизод 28. Депресняк , may include content that is owned or administered by this entity:Entity: The Orchard Music Content Type: Sound Recording
С тех пор как я открыл этот масяньский канал на Ютубе нервы мои не выдерживают. Я загружаю совершенно легальный контент. То есть все мульты с музыкой специально написанной для них. Все старое нелегальное выкинуто подчистую. И тем ни менее каждый раз когда я чего-то туда загружаю они регулярно сбрасывают мульты отписываясь что они “не смогли удостоверится что он легальный”. Я им уже десяток писем написал- не помогает. Суки честно говоря. Нервотрепка. Я разочарован в ютубе и гугле. Близок к тому чтобы бросить эту затею.. Копирайт-наци.»
Огромное количество народу выкладывает пиратские копии чужих файлов и им это делать не мешают… Потому, что они действуют в рамках неписанных правил… А вот тот, кто честно готов предоставить доступ к результатам своего труда – нарушает равновесие. Эдак и другие по этому скользкому пути могут захотеть пойти…
Комментарии к записи Копирасты против Масяни отключены

